
一、思路整理: 写了上篇文章“如何用Python编程实时监控币种拉盘或砸盘行为”之后,发现公信宝的拉盘行动每次都提前在微博告知,如下图 
而且第三次回购竟然持续两天时间,那如果能及时收到微博通知就又多了一手消息。但又不可能随时盯着微博,就想怎么用python来实时监控微博新内容。 谷歌下,大部分给出的方案是先用python模拟登陆移动版微博,然后从自己的关注列表或关注用户的UID来获得内容。但是我搞了好几次,花了几小时都没搞定。主要原因是搜索的文章基本都在3月之前,而微博的防爬虫功能会越来越完善,导致很多原来的方法失效。 正当百思不得其解时,突然想到去微信公众号里搜索,原因是可以搜索到比较新的文章,果然找到一篇使用Python爬虫爬取新浪微博评论,给我打开了思路。他是去监控他妹妹的微博内容的评论,里面并没有提到要登陆。也就是不用登陆也可以监控微博啊,干嘛还大费周折去登陆自己的账户呢。 试了下他的代码,运行下来没错误,太好了,我可以从中借鉴了。非常感谢作者公众号:编程思考。 借鉴他的方法,先爬取微博的内容。之后我就可以在此基础上编程实现自己想要的功能。 二、抓取微博内容 用移动端网页打开要监控的微博主页,比如我要监控公信宝的主页。打开之后按F12调出开发者工具→network选项卡,Hide data URLS打勾,选择XHR,找到与微博内容相关的信息,发现藏在getIndex?uid=5598561921下面,而且每次往下加载时会出现一个新的选项卡,我们监控新内容,只要第一页就行了。然后点击headers,找到我们所需要的内容Request URL,获取方式为requests.get,User-Agent,复制下来 
这样通过以下几条我们就可以获取公信宝首页的数据,需要对内容进行处理。 import requests
import json, time, datetime
user_agent = 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Mobile Safari/537.36'
header = {'User-Agent': user_agent} # 不用要cookie就行
# 用户公信宝
XHRUrl = 'https://m.weibo.cn/api/container/getIndex?uid=5598561921&luicode=10000011&lfid=100103type%3D1%26q%3D%E5%85%AC%E4%BF%A1%E5%AE%9D&containerid=1076035598561921'
r = requests.get(XHRUrl, headers=header)
# print(r.text)
json_str = r.text # 全部数据
dict_ = json.loads(json_str) # 转化为json格式 接下来就是怎么样找到我们想要的微博内容。 点击Preview,一项一项展开,我们看到有10条很整齐的数据: 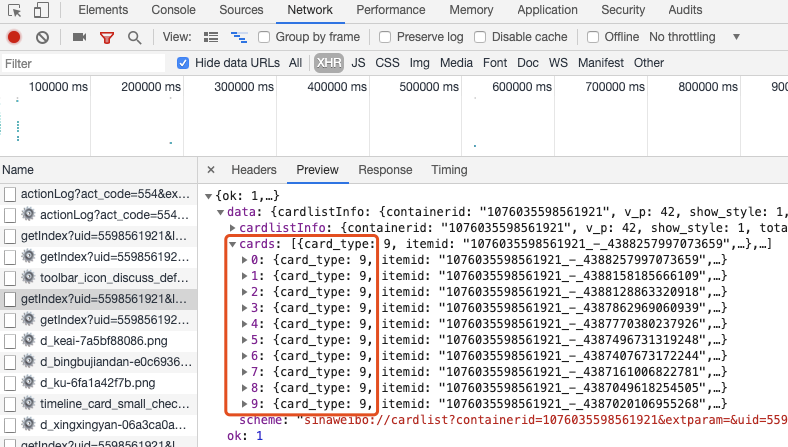
再对每个数据条进行展开,比如点击0,我们发现有个“text”与微博内容对应,那通过对字典数据的处理,找到这个内容就行了。 
n = 1 # 打印条数用
# 对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值
WB_text_List = [] # 微博内容列表
for index, card in enumerate(dict_['data']['cards']):
if dict_['data']['cards'][index]['card_type'] == 9: # {card_type: 9, 是9下面才有内容
# print(dict_['data']['cards'][index]['mblog']['id']) # 每条微博的ID
text = dict_['data']['cards'][index]['mblog']['text'] # 每条微博的内容
text = text.split('<span')[0] # 发现内容比较混杂,使用split分割字符串,隔开之后文字在新的list中第一个, 暂时去除图片
created_at = dict_['data']['cards'][index]['mblog']['created_at'] # 每条微博的发布时间
# print(n, text)
print(n, created_at, text)
WB_text_List.append(text) # 当前内容列表
n = n + 1 继续对微博内容处理,比如发现内容比较混杂,使用split分割字符串,获得主要文字内容。再加上每条微博的发布时间等等。 这样就可以准确获得当前页面的十条内容。 
三、新微博发通知 当前面容获取好之后,如果有新的内容,怎么样让程序知道呢,思考之后发现一种办法。上面不是获取了首页的内容了吗?把它当作原始数据,过段时间之后我再重新获取下每条微博,如果有微博内容不在上面列表之内,那就说明是新内容,这个时间就把内容输出,并且用钉钉来通知我,就可以实现有新内容实时监控了。 加入循环及容错处理,请见完整代码while True下面的内容即可。 如果更换监控用户怎么操作,只需要更换第一步Request URL内容来改XHRUrl即可。 这样我只需要我关注的微博内容,再也不用担心受到乱七八糟的信息干扰了。
附完整代码: import requests
import json, time, datetime
# 异常提醒用,有提示
def send_dingding_msg1(content, robot_id='你的钉钉机器人id'):
try:
msg = {
"msgtype": "text",
"text": {"content": content + '\n' + datetime.datetime.now().strftime("%m-%d %H:%M:%S")}
}
headers = {"Content-Type": "application/json ;charset=utf-8 "}
url = 'https://oapi.dingtalk.com/robot/send?access_token=' + robot_id
body = json.dumps(msg)
status = requests.post(url, data=body, headers=headers)
if status.status_code == 200:
return status.json()
# else:
# return response.json()
return status
except Exception as err:
print('钉钉发送失败', err)
user_agent = 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Mobile Safari/537.36'
header = {'User-Agent': user_agent} # 不用要cookie就行
# 用户公信宝
XHRUrl = 'https://m.weibo.cn/api/container/getIndex?uid=5598561921&luicode=10000011&lfid=100103type%3D1%26q%3D%E5%85%AC%E4%BF%A1%E5%AE%9D&containerid=1076035598561921'
r = requests.get(XHRUrl, headers=header)
# print(r.text)
json_str = r.text # 全部数据
dict_ = json.loads(json_str) # 转化为json格式
n = 1 # 打印条数用
# 对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值
WB_text_List = [] # 微博内容列表
for index, card in enumerate(dict_['data']['cards']):
if dict_['data']['cards'][index]['card_type'] == 9: # {card_type: 9, 是9下面才有内容
# print(dict_['data']['cards'][index]['mblog']['id']) # 每条微博的ID
text = dict_['data']['cards'][index]['mblog']['text'] # 每条微博的内容
text = text.split('<span')[0] # 发现内容比较混杂,使用split分割字符串,隔开之后文字在新的list中第一个, 暂时去除图片
created_at = dict_['data']['cards'][index]['mblog']['created_at'] # 每条微博的发布时间
# print(n, text)
print(n, created_at, text)
WB_text_List.append(text) # 当前内容列表
n = n + 1
while True:
try:
r = requests.get(XHRUrl, headers=header) # 使用.format()把用户id和页数倒进去
json_str = r.text # 全部数据
dict_ = json.loads(json_str) # 转化为json格式
n = 1 # 打印条数用
for index, card in enumerate(dict_['data']['cards']):
if dict_['data']['cards'][index]['card_type'] == 9: # {card_type: 9, 是9下面才有内容
# print(dict_['data']['cards'][index]['mblog']['id']) # 每条微博的ID
text = dict_['data']['cards'][index]['mblog']['text'] # 每条微博的内容
text = text.split('<span')[0] # 发现内容比较混杂,使用split分割字符串,隔开之后文字在新的list中第一个, 暂时去除图片
created_at = dict_['data']['cards'][index]['mblog']['created_at'] # 每条微博的发布时间
if not (text in WB_text_List):
print('新微博', text, sep='\n')
content = '新微博' + '\n' + text
send_msg1 = send_dingding_msg1(content)
print(send_msg1)
n = n + 1
time.sleep(5)
except Exception as err:
print("查询出错", err)
time.sleep(1)
—-
编译者/作者:杨卫祥
玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。
|